When GitHub Actions was introduced, it gave private repositories the ability to easily create a CI/CD pipeline by simply creating a yaml file within their repository. No special software was needed, no external access had to be granted to third party CI/CD systems. It just worked. One year later, this feature was made available, for free, to public repositories as well. Now, any project hosted on GitHub can enable its own CI/CD pipeline, by creating a workflow. By default, the jobs run on a GitHub hosted runner, which is a virtual machine spun up in Azure using the Standard_DS2_v2 size. Also, you have a choice of images for various operating systems and versions, which are bundled with a lot of the common libraries and SDKs that are used in projects throughout GitHub.
If you want to test your project, you have a fleet of GitHub hosted runners primed and ready to execute a request from your repository to run a workflow. The virtual machines the tests run on are replaced after each run. This means you always get a clean machine whenever you want to run a test. Which is great, and in most cases is more than enough to run a series of unit tests or even integration tests. The workflows have a maximum duration of 6 hours, after which the job is automatically canceled and the runner is cleaned up.
But what happens if you want to run your tests on an operating system that is not in the list of supported images? Or what if you need more disk space? More CPU/Memory? What if you’re testing a huge project like Flatcar which needs to build many packages as part of their pipeline? What if you need access to a GPU, or some other specialized hardware?
Well, in that case GitHub recommends you set up your own self-hosted runners.
But can you do this easily? Does it require a huge learning curve? Complicated setups? I mean, I want my own runners, but not if I have to go through piles of howtos to get them.
The answer is: yes, it can be done easily. We’ll get to that soon. But first, we need to understand the problem that’s being solved.
About self hosted runners
Self hosted runners are compute resources (virtual machines, containers or bare metal servers), on which you install and run the GitHub Actions Runner. This runner will then connect to GitHub, and become available within your repository, organization or enterprise. You can then target that particular runner in your workflow, using labels.
There are two ways a runner can be registered:
- Persistent
- Ephemeral
Persistent runners are set up and manually maintained by you. You install them, add them to your repository and use them however many times you wish. Persistent runners are capable of running as many jobs as you throw at them. However, it falls onto you, to make sure that the machine is cleaned up and in working order after each job run. Otherwise, new jobs that get scheduled to it will most likely fail, or at the very best they will give you unreliable results.
Ephemeral runners accept only one job, after which they are automatically removed by GitHub from the list of available runners. This ensures that you always get a fresh machine to run your tests, but in this case, you need to implement some sort of auto-scaling that will tear down the runner that completed a job, and replace it with a new one. These runners give you the best experience, as they are fresh and untouched by previous tests.
We’ll be focusing on ephemeral runners in this article, and a way to automatically scale and maintain a pool of those.
The challenges of auto scaling
Auto-scaling of runners is done using GitHub web hooks. Whenever a new workflow job is triggered, GitHub will push an event via web hooks that will let you know that a job has be queued and a new worker is needed. If a worker is already online and idle, that worker is selected, and another web hook is triggered that lets you know a job is now in_progress. Finally, when a job finishes, a final web hook is triggered with a completed message. As part of the queued web hook, we also get a list of labels that the job is targeting.
We can use this information to implement our auto-scaling solution. Now here comes the tricky part. We need some sort of automation that will spin up runners that match the requested label. A label describes the needs of the workflow job. So we need a way to model that request into an operation that will set up exactly the kind of runner that is suited for that job. If your workflow requests a label called gpu, you need to spin up a runner with access to a GPU. If your workflow requests a label called hpc you may need to set up a runner with access to lots of CPU and memory. The idea is to be able to define multiple types of runners and make them available to your workflows. After all, this is the reason you might decide to use self-hosted runners instead of the default ones provided by GitHub.
You may have your own specialized hardware that you want to make available to a workflow, or you may have some spare hardware gathering dust and want to give it new life. Or you may have access to multiple cloud accounts that you could leverage to spin up compute resources of various types.
Introducing: GitHub Actions Runners Manager (garm)
Garm is a self-hosted, automated system that maintains pools of GitHub runners on potentially any IaaS which has an API that will allow us to create compute resources. Garm is a single binary written in Go that you can run on any machine, within your private network. It requires no central management system, it doesn’t need to call home and is fully open source under the Apache 2.0 license.
Garm is meant to be easy to set up, easy to configure and hopefully, something you can forget about once it’s up and running. There are no complicated concepts to understand, no lengthy setup guide, no administrator guide that could rival the New York phone book in thickness. Garm is a simple app that aims to stay out of your way.
The only API endpoint that needs to be public, is the web hook endpoint, which GitHub calls into. It’s how GitHub lets garm know that a new runner is needed and that old runners need to be cleaned up.
Everything else can be hidden away behind a reverse proxy.
Where can garm create compute resources?
Right now garm has native support for LXD and an external provider for OpenStack and Azure. The current external OpenStack and Azure Providers are just a sample at the moment, but it can be used for testing and as an example for creating new external providers that can enable garm to leverage other clouds. External providers are executables that garm calls into, to manage the lifecycle of instances that end up running the GitHub Action Runner. They are similar to what containerd does when it comes co CNIs. As long as those binaries adhere to the required interface, garm can use them.
Sounds like garm spins up virtual machines?
In short: yes, but it doesn’t have to use VMs exclusively. I’ll explain.
We focused on virtual machines for the initial release because of their isolation from the host. Running workflows for public repositories is not without risks, so we need to be mindful of where we run jobs. The isolation offered by a virtual machine is desirable in favor of that of a container. That being said, there is no reason why a provider can’t be written for any system that can spin up compute resources, including containers.
In fact, writing a provider is easy, and you already have two examples of how to do it. With a little over 400 lines of bash, you could write a provider for virtually anything that has an API. And it doesn’t have to be bash. You could use anything you prefer, as long as the API for external providers is implemented by your executable.
In any case, I think it’s time to have a look at what garm can do.
Defining repositories/organizations
This article won’t go into details about how to set up garm. Those details are laid out in the project home page on GitHub. Instead, I’ll show you how to use it to manage your runners.
Garm has three layers:
- Repositories or organizations
- Pools of runners
- The runners
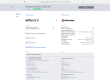
Repositories and organizations can have multiple pools. Each pool can have different settings, can each use a different provider and will spin up multiple runners of the same type. When defining a new repository or organization, we need a Personal Access Token (PAT) to be configured in garm. Repositories use PATs to request registration tokens for runners, list existing runners and potentially forcefully remove them if the compute instance becomes defunct (on the roadmap). You can define multiple PATs and configure each repository or organization to use a different one.
Here is an example of defining a repository:
Creating pools
A pool of runners will create a number of runners of the same type inside a single provider. You can have multiple pools defined for your repository and each pool may have different settings with access to different providers. You can create one pool on LXD, another pool on OpenStack, each maintaining runners for different operating systems and with different sizes.
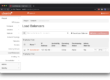
Let’s define a pool for the previously created repository:
We created a pool on LXD using default as a flavor and ubuntu:20.04 as an image. For LXD, garm maps flavors to profiles. The image names are the same images you would use to spin up virtual machines using the lxc command. So this pool will spin up an Ubuntu 20.04 image from the usual ubuntu: remote and will apply the default profile.
You can create new LXD profiles with whatever resources your runners need. Need multiple disks, more CPU or access to a number of different networks? Add them to the profile. The VMs that will be created with that profile will automatically have the desired specifications.
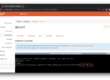
Let’s enable the pool and have it spin up the runners:
By default, when you create a new pool, the maximum number of runners will be set to 5 and the minimum idle runners will be set to 1 (configurable during create). This means that this particular pool will create a maximum number of 5 runners. The minimum idle runner option, attempts to maintain at least 1 runner in idle state, ready to be used by a GitHub workflow.
If you want more total runners or more idle runners, you can update the pool:
Now let’s add a new pool for the same repository, but this time we’ll add it on the external OpenStack provider:
On OpenStack flavor maps to the OpenStack flavor and image maps to the glance image. The flavor in OpenStack, aside from the basic resources it can configure, has the ability to target specific hosts via host aggregates and grant access to specialized hardware like GPUs, FPGAs, etc. If you need runners with access to special hardware, have a look at host aggregates.
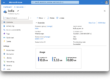
Now that we have our pools and a few runners up and running, let’s try them out in a workflow:
We can see that we have five runners in total. Three on the LXD pool and another 2 on the OpenStack pool. As we trigger workflows in github, garm spins up new runners to replace the ones that are currently being used, maintaining that minimum idle runner count.
That’s all. If you want to try it out, head over to the project home page on GitHub and take it for a spin. Fair warning, this is an initial release, so if you run into any trouble, drop us a line.