In the previous article in this series we gave you a quick overview of why OpenStack and Windows Nano Server provide some of the most exciting elements in the current Windows ecosystem. In this article we are going to expand on those elements, and also give you the tools you need to deploy your own Hyper-Converged cloud using our OpenStack Windows Liberty components along with Ubuntu’s OpenStack Linux ones!
Why is everyone so excited about Windows Nano Server?
Nano Server is a new installation option for Windows Server 2016, reducing the overall footprint to just a few hundreds MB of disk space. The resulting deployed OS is thus way faster to deploy and to boot, reducing drastically also the overall amount of updates and reboots required during daily management. In short, it’s an OS built for a cloud age and huge leap forward compared to traditional GUI based Windows deployments.
Nano images are designed to be purpose built for each deployment. That means that if you want a Windows Server that is just a hypervisor, you can build the image just with that role installed and nothing else. In this article we are going to focus on three main roles:
- Compute (Cloudbase OpenStack components and Hyper-V)
- Clustering
- Storage (Storage Spaces Direct)
Storage Spaces Direct (S2D)
Aside from Nano itself, this is one of the features I am most excited about and a key element in allowing a hyper-converged scenario on Windows Server. Storage Spaces Direct is an evolution of Storage Spaces introduced in Windows Server 2012, with one important difference – it allows you to use locally attached storage. This means that you can use commodity hardware to build you own scale out storage at a fraction of the cost of a normal enterprise storage solution. This also means that we can create a hyper-converged setup where all Hyper-V compute nodes are clustered together and become bricks in a scale-out storage system.

Ok, Ok… lets deploy already!
Before we begin, a word of warning. Windows Nano Server is in Technical Preview (it will be released as part of Windows Server 2016). The following deployment instructions have been tested and validated on the current Technical Preview 4 and subject to possible changes in the upcoming releases.
Prerequisites
We want to deploy an OpenStack cloud on bare metal. We will use Juju for orchestration and MAAS (Metal as a Service) as a bare metal provider. Here’s our requirements list. We kept the number of resources to the bare minimum, which means that some features, like full components redundancy are left for one of the next blog posts:
- MAAS install
- Windows Server 2016 TP4 ISO
- A Windows 10 or Windows Server 2016 installation. You will need this to build MAAS images.
- One host to be used for MAAS and controller related services
- Should have at least three NICs (management, data, external)
- At least 4 hosts that will be used as Hyper-V compute nodes
- Each compute node must have at least two disks
- Each compute node should have at least two NICs (management and data)
As an example, our typical lab environment uses Intel NUC servers. They are great for testing and have been our trusty companions throughout many demos and OpenStack summits. These are the new NUCs that have one mSATA port and an one M.2 port. We will use the M.2 disk as part of the storage spaces direct storage pool. Each NUC has one extra USB 3 ethernet NIC that acts as a data port.
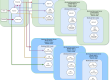
Here’s a detailed list of the nodes configuration:
Node 1 Ubuntu 14.04 LTS MAAS on bare metal with 4 VMs running on KVM. 3 NICs, each one attached to a standard linux bridge. eth0 (attached to br0) is the MAAS publicly accessible NIC. It will be used by neutron as an external NIC. eth1 (attached to br1) is connected to an isolated physical switch. This will be the management port for nodes deployed using MAAS. eth2 (attached to br2) is connected to an isolated physical switch. This will be the data port used for tenant traffic.
This node also hosts 4 virtual machines:
Name Tags Purpose NICs vCPU RAM Disk VM01 state Juju state machine eth0 attached to br1 2 2 GB 20 GB VM02 s2d-proxy Manages the Nano Server S2D cluster. eth0 attached to br1 2 2 GB 20 GB VM03 services OpenStack controller eth0 attached to br1 (maas management)
eth1 attached to br2 (isolated data port)
eth3 attached to br0 (external network)4 8 GB 80 GB VM04 addc Active Directory Controller eth0 attached to br1 2 2 GB 20 GB
The rest of the nodes look like this:
Node 2, 3, 4, 5 Nano Server Hyper-V compute nodes with Cloudbase OpenStack components Tag: nano 2 NICs one NIC attached to the MAAS management switch (PXE booting must be enabled and set as first boot option) one NIC attached to the isolated data switch
Install MAAS
We are not going to go into too much detail over this as the installation process has been very well documented in the official documentation. Just follow this article, it’s very simple and straightforward. Make sure to configure your management network for both DHCP and DNS. After installing MAAS, it’s time to register your nodes in MAAS. You can do so by simply powering them on once. MAAS will automatically enlist them.
You can log in the very simple and intuitive MAAS web UI available at http://<MAAS>/MAAS and check that you nodes are properly enlisted.
Assign tags to your MAAS nodes
Tags allow Juju to request hardware with specific requirements to MAAS for specific charms. For example the Nano Server nodes will have a “nano” tag. This is not necessary if your hardware is completely homogenous. We listed the tags in the prerequisite section.
This can be done either with the UI by editing each individual node or with the following Linux CLI instructions.
Register a tag with MAAS:
|
1 |
maas root tags new name='state' |
|
1 2 3 4 5 6 7 8 |
# <system_id> is the node's system ID. You can fetch it from MAAS # using: # maas root nodes list # and usually has the form of: # node-2e8f4d32-7859-11e5-8ee5-b8aeed71df42 # You can also get the ID of the node from the MAAS web ui by clicking on the node. # The ID will be displayed in the browsers URL bar. maas root tag update-nodes state add="<system_id>" |
Build Windows images
After you have installed MAAS, we need to build Windows images. For this purpose, we have a set of PowerShell CmdLets that will aid you in building the images. Log into your Windows 10 / Windows Server 2016 machine and open an elevated PowerShell prompt.
First lets download some required packages:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# install Chocolatey package provider Get-PackageProvider -Name chocolatey -ForceBootstrap Set-PackageSource -Name Chocolatey -Trusted:$true # Install Git Install-Package -Source Chocolatey git # Install Notepad++ (optional). Any other good editor will do as well. Install-Package -Source Chocolatey notepadplusplus # Add git to your path $env:PATH += ";${env:ProgramFiles}\Git\cmd" # check that git works git --version # If you wish to make the change to your $env:PATH permanent # you can run: # setx PATH $env:PATH |
Download the required resources:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
$ErrorActionPreference = "Stop" mkdir $HOME\hyper-c -ErrorAction SilentlyContinue cd $HOME\hyper-c # Fetch scripts and commandlets Invoke-WebRequest https://bit.ly/FastWebRequest -OutFile FastWebRequest.psm1 Import-Module .\FastWebRequest.psm1 Invoke-FastWebRequest -Uri "https://the.earth.li/~sgtatham/putty/latest/x86/pscp.exe" Invoke-FastWebRequest -Uri "https://the.earth.li/~sgtatham/putty/latest/x86/putty.exe" # Fetch nano image tools git clone https://github.com/cloudbase/cloudbase-init-offline-install.git nano-image-tools pushd nano-image-tools git checkout nano-server-support git submodule init git submodule update popd # Fetch Windows imaging tools git clone https://github.com/cloudbase/windows-openstack-imaging-tools.git windows-imaging-tools pushd windows-imaging-tools git checkout experimental popd |
You should now have two extra folders in your home folder:
- generate-nano-image
- windows-openstack-imaging-tools-experimental
Generate the Nano image
Lets generate the Nano image first:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
cd $HOME\hyper-c\nano-image-tools # Change this to your actual ISO location $isoPath = "$HOME\Downloads\Windows_Server_2016_Technical_Preview_4.ISO" # This will be your default administrator password. Change this to whatever you prefer $password = ConvertTo-SecureString -AsPlaintext -Force "P@ssw0rd" # This is the path of your Nano baremetal image $targetPath = "$HOME\DiskImages\Nano.raw.tgz" # If your hardware needs extra drivers for NIC or storage, you can add it by # passing the -ExtraDriversPaths option to the script. .\NewNanoServerImage.ps1 -IsoPath $isoPath -TargetPath $targetPath ` -AdministratorPassword $password -Platform BareMetal ` -Compute -Storage -Clustering -MaxSize 1500MB ` -AddCloudbaseInit -AddMAASHooks cd .. # Change to match you MAAS host address $MAAS_HOST = "192.168.200.10" # Copy the Nano image to the MAAS host, change the credentials accordingly .\pscp.exe "$targetPath" "cloudbase@${MAAS_HOST}:" |
Now, SSH into your MAAS node and upload the image in MAAS using the following commands:
|
1 2 3 4 5 6 7 8 9 10 |
# Get your user's MAAS API key from the following URL: http://${MAAS_HOST}/MAAS/account/prefs/ # Note: the following assumes that your MAAS user is named "root", replace it as needed maas login root http://${MAAS_HOST}/MAAS # Upload image to MAAS # At the time of this writing, MAAS was version 1.8 in the stable ppa # Windows Server 2016 and Windows Nano support has been added in the next stable release. # as such, the images we are uploading, will be "custom" images in MAAS. With version >= 1.9 # of MAAS, the name of the image will change from win2016nano to windows/win2016nano # and the title will no longer be necessary maas root boot-resources create name=win2016nano title="Windows Nano server" architecture=amd64/generic filetype=ddtgz content@=$HOME/Nano.raw.tgz |
The name is important. It must be win2016nano. This is what juju expects when requesting the image from MAAS for deployment.
Generate a Windows Server 2016 image
This will generate a MAAS compatible image starting from a Windows ISO, it requires Hyper-V:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
cd $HOME\hyper-c\windows-imaging-tools # Mount Windows Server 2016 TP4 ISO # Change path to actual ISO $isoPath = $HOME\Downloads\WindowsServer2016TP4.iso # Mount the ISO $driveLetter = (Mount-DiskImage $isoPath -PassThru | Get-Volume).DriveLetter $wimFilePath = "${driveLetter}:\sources\install.wim" Import-Module .\WinImageBuilder.psm1 # Check what images are supported in this Windows ISO $images = Get-WimFileImagesInfo -WimFilePath $wimFilePath # Get the Windows images available in the ISO $images | select ImageName # Select the first one. Note: this will generate an image of Server Core. # If you want a full GUI, or another image, choose from the list above $image = $images[0] $targetPath = "$HOME\DiskImages\Win2016.raw.tgz" # Generate a Windows Server 2016 image, this will take some time! # This requires Hyper-V for running the instance and installing Windows updates # If your hardware needs extra drivers for NIC or storage, you can add it by # passing the -ExtraDriversPath option to the script. # You also have the option to install Windows Updates by passing in the -InstallUpdates option New-MAASImage -WimFilePath $wimFilePath -ImageName $image.ImageName ` -MAASImagePath $targetPath -SizeBytes 20GB -Memory 2GB ` -CpuCores 2 cd .. # Copy the Nano image to the MAAS host .\pscp.exe "$targetPath" "cloudbase@${MAAS_HOST}:" |
Upload the image to MAAS:
|
1 2 3 4 5 6 7 |
# upload image to MAAS # At the time of this writing, MAAS was version 1.8 in the stable ppa # Windows Server 2016 and Windows Nano support has been added in the next stable release. # as such, the images we are uploading, will be "custom" images in MAAS. With version >= 1.9 # of MAAS, the name of the image will change from win2016 to windows/win2016 # and the title will no longer be necessary maas root boot-resources create name=win2016 title="Windows 2016 server" architecture=amd64/generic filetype=ddtgz content@=$HOME/Win2016.raw.tgz |
As with the Nano image, the name is important. It must be win2016.
Setting up Juju
Now the fun stuff begins. We need to fetch the OpenStack Juju charms and juju-core binaries, and bootstrap the juju state machine. This process is a bit more involved, because it requires that you copy the agent tools on a web server (any will do). A simple solution is to just copy the tools to /var/www/html on your MAAS node, but you can use any web server at your disposal .
For the juju deployment you will need to use an Ubuntu machine. We generally use the MAAS node directly in our demo setup, but if you are running Ubuntu already, you can use your local machine.
Fetch the charms and tools
For your convenience we have compiled a modified version of the agent tools and client binaries that you need to run on Nano Server. This is currently necessary as we’re still submitting upstream the patches for Nano Server support, so this step won’t be needed by the time Windows Server 2016 is released.
From your Ubuntu machine:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# install some dependencies # add the juju stable ppa. We need this to get juju-deployer sudo apt-add-repository -y ppa:juju/stable # install packages sudo apt-get update sudo apt-get -y install unzip git juju-deployer mkdir -p $HOME/hyper-c cd $HOME/hyper-c # Download juju-core with Nano support and the Hyper-C charms git clone https://github.com/cloudbase/hyper-c.git hyper-c-master wget "https://github.com/cloudbase/hyper-c/releases/download/hyper-c/juju-core.zip" unzip juju-core.zip # Add the client folder to the $PATH. You can make this change permanend # for the current user by adding: # export PATH="$HOME/hyper-c/juju-core/client:$PATH" # to $HOME/.bashrc export PATH="$HOME/hyper-c/juju-core/client:$PATH" # test that the juju client is in your path juju version |
If everything worked as expected, the last command should give you the Juju version.
Configuring the Juju environment
If you look inside $HOME/hyper-c/juju-core you will see a folder called tools. You need to copy that folder to the web server of your choice. It will be used to bootstrap the state machine. Lets copy it to the MAAS node:
|
1 2 3 4 |
# NOTE: If you are following this article directly on your MAAS node, # you can skip these steps cd $HOME/hyper-c scp -r $HOME/hyper-c/juju-core/tools cloudbase@$MAAS_HOST:~/ |
Now, ssh into your MAAS node and copy these files in a web accessible location:
|
1 2 |
sudo cp -a $HOME/hyper-c/juju-core/tools /var/www/html/ sudo chmod 755 -R /var/www/html/tools |
Back on your client machine, create the juju environments boilerplate:
|
1 |
juju init |
This will create a folder $HOME/.juju. Inside it you will have a file called environments.yaml that we need to edit.
Edit the environments file:
|
1 |
nano $HOME/.juju/environments.yaml |
We only care about the MAAS provider. You will need to navigate over to your MAAS server under http://${MAAS_HOST}/MAAS/account/prefs/ and retrieve the MAAS API key like you did before.
Replace your environments.yaml to make it look like the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
default: maas environments: maas: type: maas # this is your MAAS node. Replace "MAAS_IP" with the actual hostname or IP maas-server: 'http://MAAS_IP/MAAS/' # This is where you uploaded the tools in the previous step. Replace "MAAS_IP" with actual hostname or IP agent-metadata-url: "http://MAAS_IP/tools" agent-stream: "released" maas-oauth: 'maas_API_key' # This will become you juju administrative user password # you may use this password to log into the juju GUI admin-secret: 'your_secret_here' disable-network-management: false bootstrap-timeout: 1800 |
Before you bootstrap the environment, it’s important to know if the newly bootstrapped state machine will be reachable from your client machine. For example, If you have a lab environment where all your nodes are in a private network behind MAAS, where MAAS is also the router for the network it manages, you will need to do two things:
- enable NAT and ip_forward on your MAAS node
- create a static route entry on your client machine that uses the MAAS node as a gateway for the network you configured in MAAS for your cluster
Enable NAT on MAAS:
|
1 2 3 4 5 6 7 8 9 10 |
# enable MASQUARADE # br0 publicly accessible interface # br1 MAAS management interface (PXE for nodes) /sbin/iptables -t nat -A POSTROUTING -o br0 -j MASQUERADE /sbin/iptables -A FORWARD -i br0 -o br1 -m state --state RELATED,ESTABLISHED -j ACCEPT /sbin/iptables -A FORWARD -i br1 -o br0 -j ACCEPT # enable ip_forward echo 'net.ipv4.ip_forward=1' >> /etc/sysctl.conf sysctl -p |
Add a static route on your client:
|
1 2 3 |
# $MAAS_HOST was defined above in the sections regarding image generation # NOTE: this is not needed if you are running the juju client directly on your MAAS node route add -net 192.168.2.0 255.255.255.0 gw $MAAS_HOST |
You are now ready to bootstrap your environment:
|
1 2 |
# Adapt the tags constraint to your environment juju bootstrap --debug --show-log --constraints tags=state |
Deploy the charms
You should now have a fully functional juju environment with Windows Nano Server support. Time to deploy the charms!
This is the last step in the deployment process. For your convenience, we have made a bundle file available inside the repository. You can find it in:
|
1 |
$HOME/hyper-c/hyper-c-master/openstack.yaml |
Make sure you edit the file and set whatever options applies to your environment. For example, the bundle file expects to find nodes with certain tags. Here is an example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
s2d-proxy: num_units: 1 charm: local:win2016/s2d-proxy branch: lp:cloudbaseit/s2d-proxy options: # Change this to an IP address that matches your environment. # This IP address should be in the same network as the IP addresses # you configured your MAAS cluster to assign to your nodes. Make sure # that this IP cannot be allocated to any other node. This can be done # by leaving a few IP addresses out of the static and dynamic ranges MAAS # allocates from. # For example: 192.168.2.10-192.168.2.100 where 192.168.2.0-192.168.2.9 # are left for you to decide where to allocate them. static-address: 192.168.2.9 # change this tag to match a node you want to target constraints: "tags=s2d-proxy" nova-hyperv: num_units: 4 charm: local:win2016nano/nova-hyperv branch: lp:cloudbaseit/nova-hyperv options: use-bonding: false # These are all the MAC addresses from all the nodes that are supposed to be # used as data ports. You can find these ports in MAAS under node details # Make sure you change this to match your environment. data-port: "3c:18:a0:05:cd:1c 3c:18:a0:05:cd:07 3c:18:a0:05:cd:22 3c:18:a0:05:cd:1e" network-type: "hyperv" openstack-version: "liberty" constraints: "tags=nano" |
Pay close attention to every definition in this file. It should precisely mirror your environment (tags, MAC addresses, IP addresses, etc). A misconfiguration will yield unpredictable results.
Use juju-deployer to deploy everything with just one command:
|
1 2 |
cd $HOME/hyper-c/hyper-c-master juju-deployer -L -S -c openstack.yaml |
It will take a while for everything to run, so sit back and relax while your environment deploys. There is one more thing worth mentioning. Juju has a gorgeous web GUI. Its not resource intensive, so you can deploy it to your state machine. Simply:
|
1 |
juju deploy juju-gui --to 0 |
You will be able to access it using the IP of the state machine. To get the ip simply do:
|
1 |
juju status --format tabular |
The user name will be admin and the password will be the value you set for admin-secret, set in juju’s environments.yaml.
At the end of this you will have the following setup:
- Liberty OpenStack cloud (with Ubuntu and Cloudbase components)
- Active Directory controller
- Hyper-V compute nodes
- Storage Spaces Direct
Access your OpenStack environment
Get the IP of your Keystone endpoint
|
1 |
juju status --format tabular | grep keystone |
Export the required OS_* variables (you can also put them in your .bashrc):
|
1 2 3 4 5 6 7 8 |
export OS_USERNAME=cbsdemo export OS_PASSWORD=Passw0rd export OS_TENANT_NAME=admin export OS_AUTH_URL=http://<keystone_ip>:35357/v2.0/ # Let's list the Nova services, including the four Nano Server compute nodes sudo apt-get install python-novaclient -y nova service-list |
You can access also Horizon by fetching its IP from Juju and open it in your web browser:
|
1 |
juju status --format tabular | grep openstack-dashboard |
What if something went wrong?
The great thing in automated deployments is that you can always destroy them and start over!
|
1 |
juju-deployer -TT -c openstack.yaml |
Form here you can run again:
|
1 |
juju-deployer -L -S -c openstack.yaml |
Video
You can also watch the whole deployment process in this video.
What’s next?
Stay tuned, in the next posts, we’ll show how to add Cinder volume on top of Storage Spaces Direct and how to easily add fault tolerance to your controller node (the Nano Server nodes are already fault tolerant).
You can also start deploying some great guest workload on top of your OpenStack cloud, like SQL Server, Active Directory, SharePoint, Exchange etc using our Juju charms!
I know this has been a long post, so if you managed to get this far, congratulations and thank you! We are curious to hear how you will use Nano Server and storage spaces direct!

Thanks for this Great post. Do I need to setup the vms in kvm or will juju do this for me?
Hi Will,
In the setup we described, the virtual machines need to be manually created and enlisted in MAAS. We didn’t list those steps as well, as the post was already quite long as is. You can find all the required information about using virtual machines in MAAS, here: https://maas.ubuntu.com/docs/nodes.html#virtual-machine-nodes